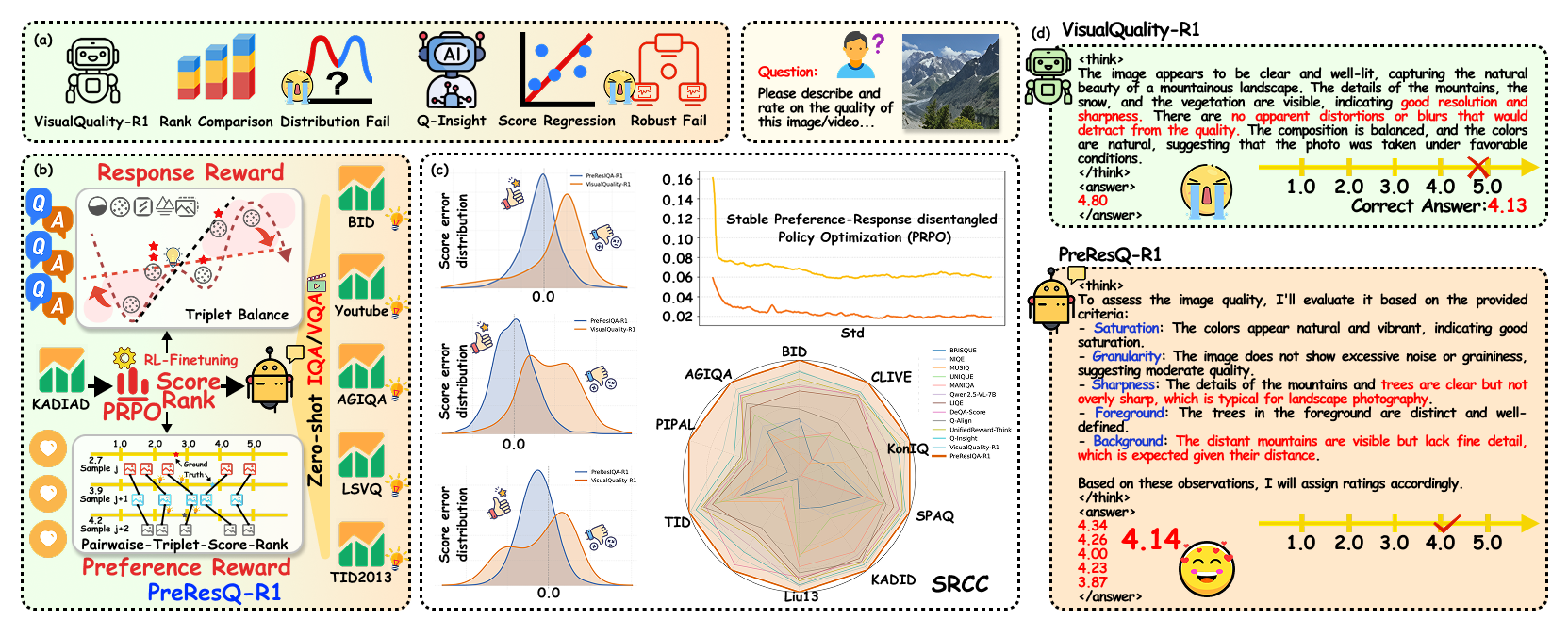
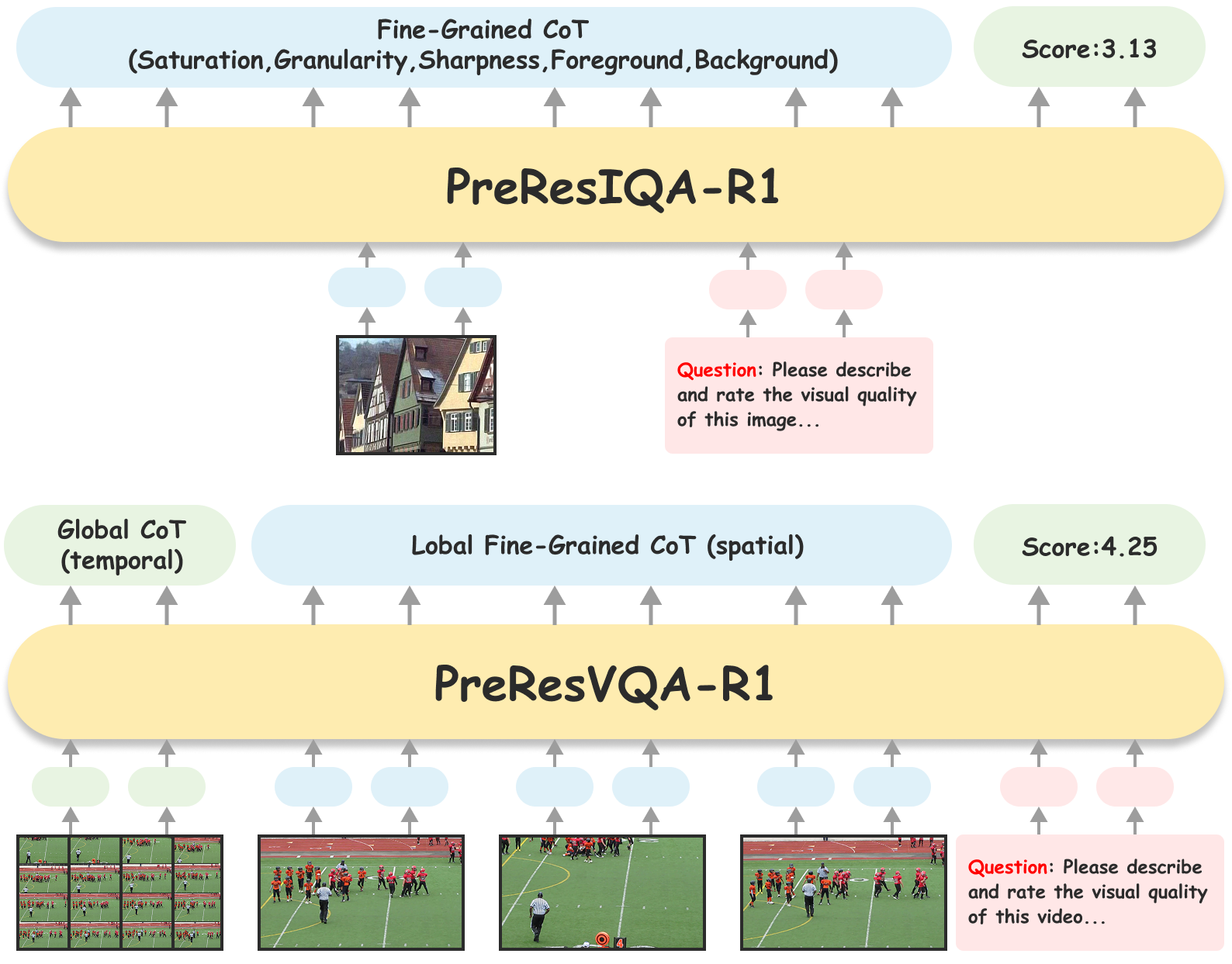
Visual Quality Assessment (QA) seeks to predict human perceptual judgments of visual fidelity. While recent multimodal large language models (MLLMs) show promise in reasoning about image and video quality, existing approaches mainly rely on supervised fine-tuning or rank-only objectives, resulting in shallow reasoning, poor score calibration, and limited cross-domain generalization. We propose PreResQ-R1, a Preference–Response Disentangled Reinforcement Learning framework that unifies absolute score regression and relative ranking consistency within a single reasoning-driven optimization scheme. Unlike prior QA methods, PreResQ-R1 introduces a dual-branch reward formulation that separately models intra-sample response coherence and inter-sample preference alignment, optimized via Group Relative Policy Optimization (GRPO). This design encourages fine-grained, stable, and interpretable chain-of-thought reasoning about perceptual quality. To extend beyond static imagery, we further design a global–temporal and local–spatial data flow strategy for Video Quality Assessment. Remarkably, with reinforcement fine-tuning on only 6K images and 28K videos, PreResQ-R1 achieves state-of-the-art results across 10 IQA and 5 VQA benchmarks under both PLCC and SRCC metrics. Beyond quantitative gains, it produces human-aligned reasoning traces that reveal the perceptual cues underlying quality judgments. Code and model are available.
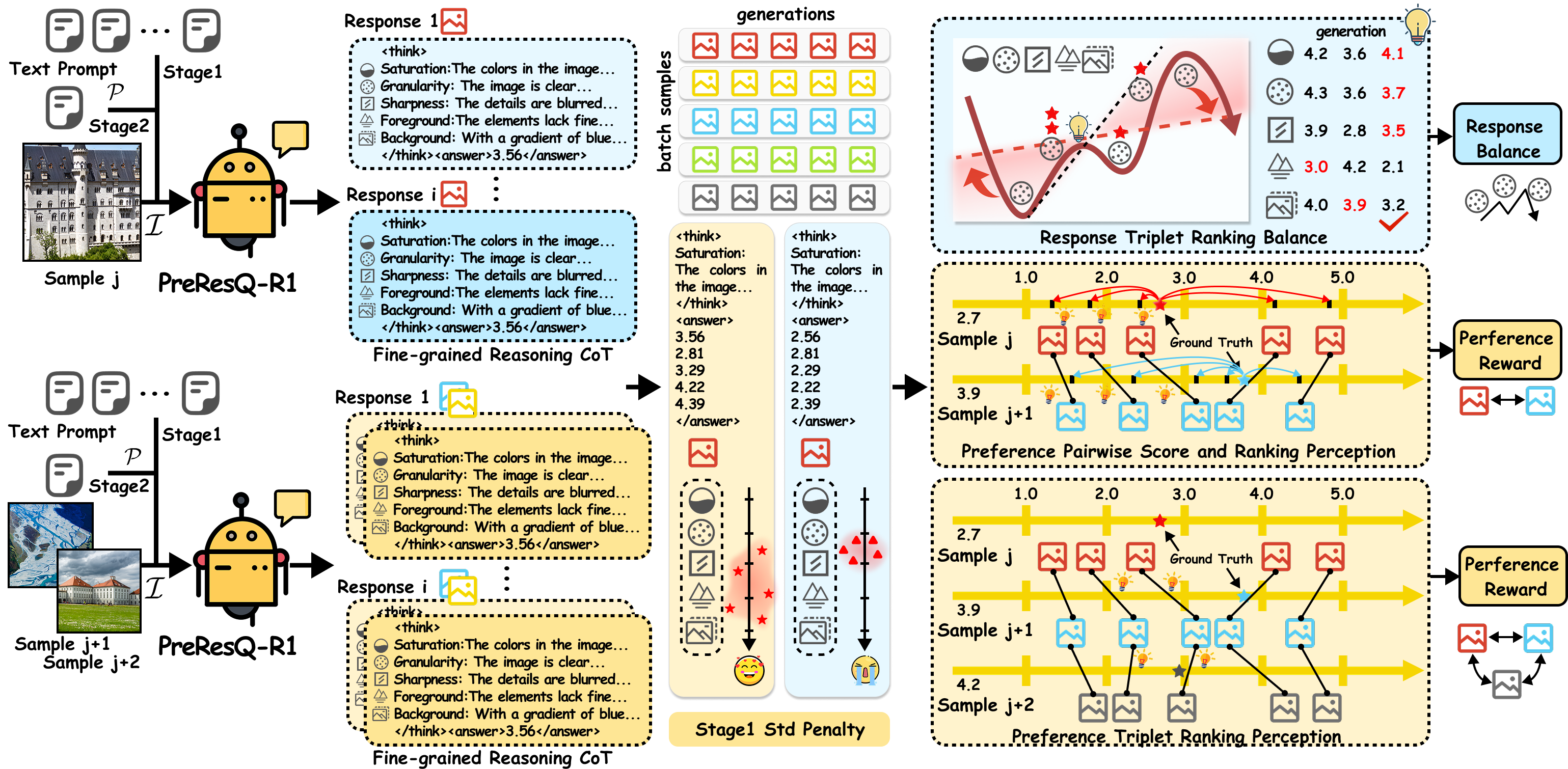
🌟🌟🌟 Overall training framework of PreResQ-R1 via RL2RS. Given an sample batch with a shared text prompt, PreResQ-R1 generates K responses.
🌟🌟🌟 To quickly activate CoT differences and then access generation stability, we introduce the response penalty and fine-grained triplet-response balance reward.
🌟🌟🌟 To jointly enhance the robustness of ranking and score ability, we introduce the preference pairwise-and-triplet score-and-ranking reward for GRPO.
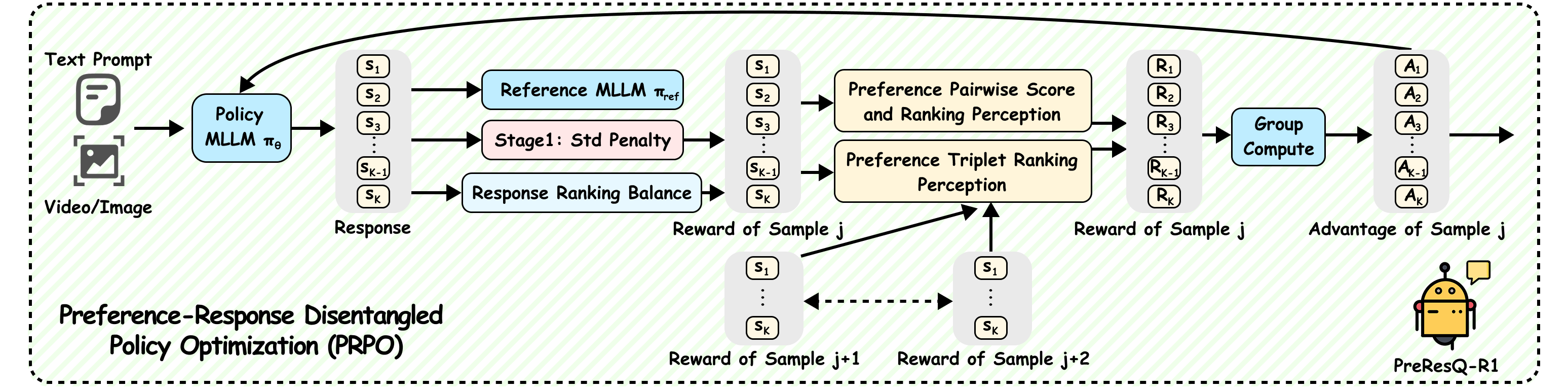
🌟🌟🌟 Pipeline of the Preference-Response Disentangled Policy Optimization (PRPO), which applies response ranking response balance reward, and preference pairwise score and ranking reward, and preference triplet ranking reward to optimize group policy learning.

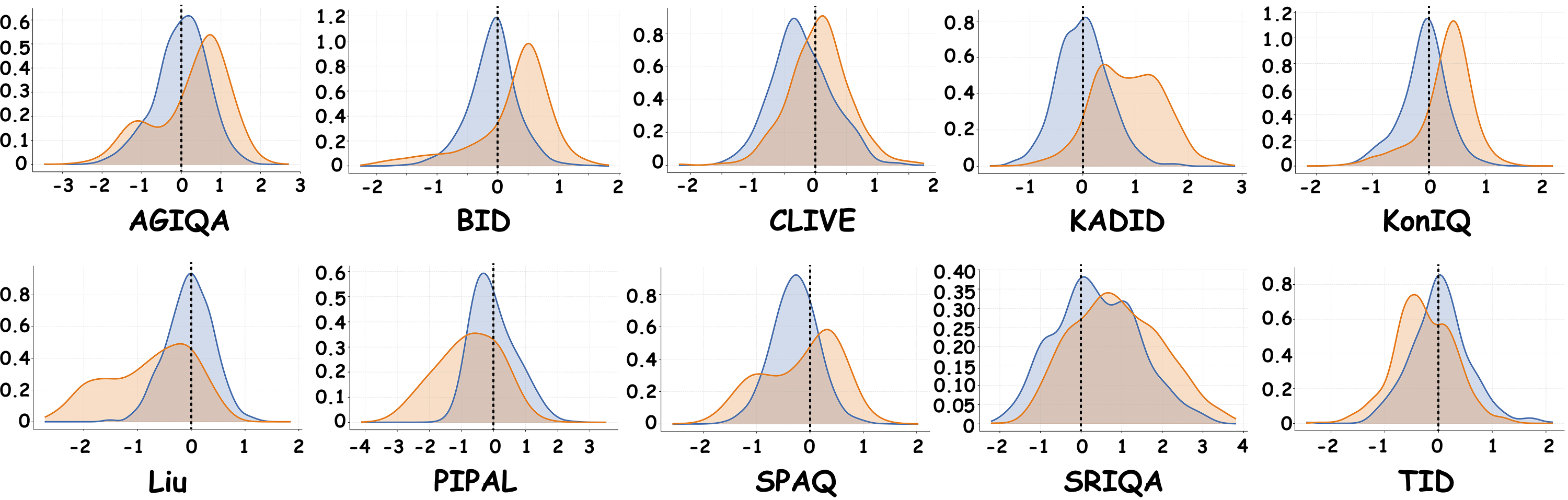
🌟🌟🌟 Comparison between PreResQ-R1 and VisualQuality-R1 on distribution of difference between answer and ground truth. The horizontal axis represents the error, and the vertical axis represents the relative proportion. The closer the distribution is to 0, the better the model performance is. Blue and Orange represents PreResQ-R1 and VisualQuality-R1.






@article{Bratrix,
title={PreResQ-R1: Towards Fine-Grained Rank-and-Score Reinforcement Learning for Image Quality Assessment via Preference–Response Disentangled Policy Optimization},
author={Zehui Feng, Tian Qiu, Tong Wu, Huayuan Xu, Ting Han},
journal={arXiv preprint arXiv:},
year={2025}
}